
Hi there!
I am Jorge. I am currently developing software/hardware with the ZCU111 board. I am using PYNQ version 2.7.
My goal is the following:
I am acquiring an RF signal through the ADC on the PL and I want to receive it on the PS. For this, I have used the following schematic:
SCHEMATIC:

AXI DMA block config:

Subset Converter block config:

FIFO block config:
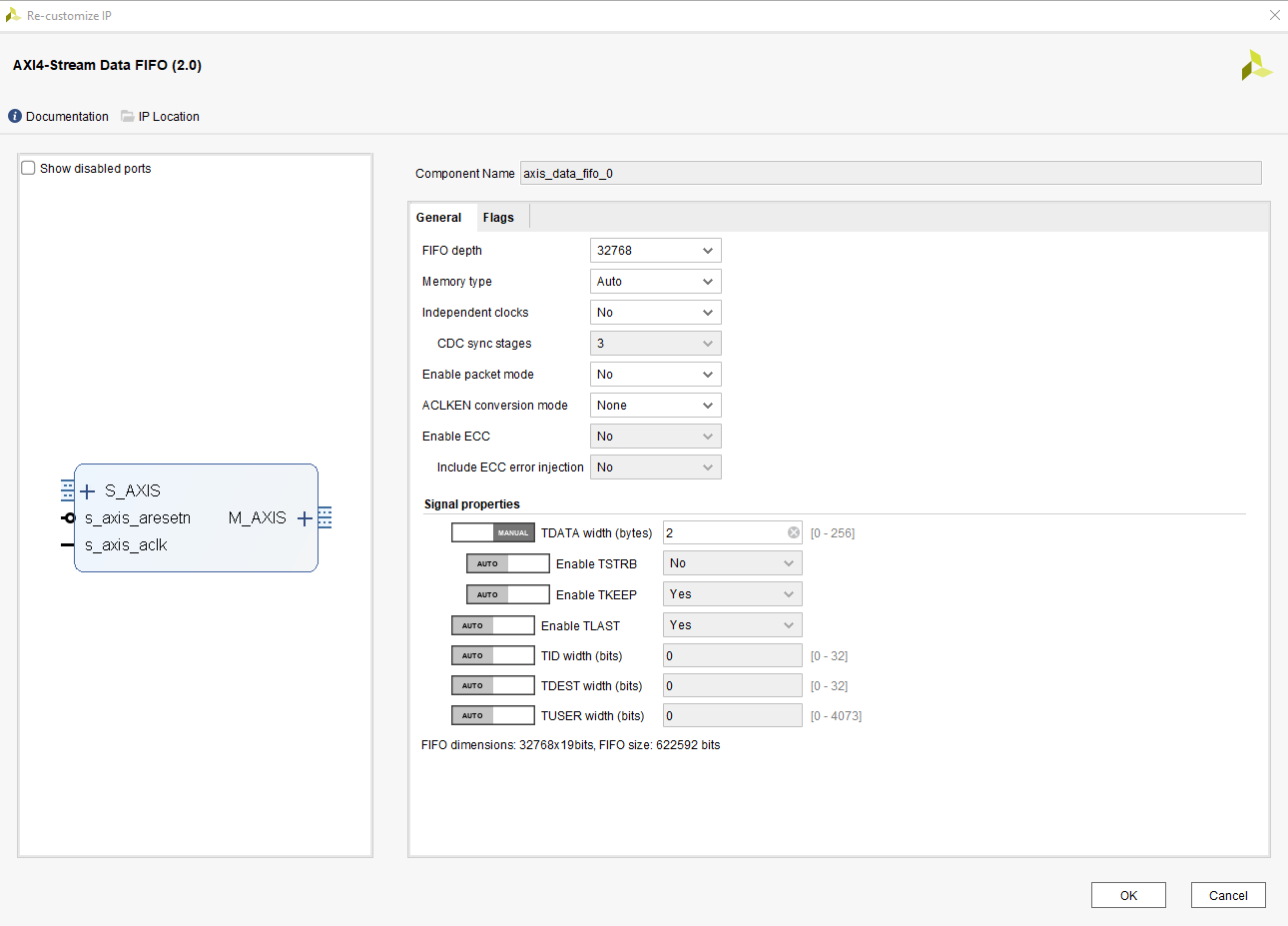
At the moment, I am only using one channel. The RF Data Converter acquires the signal which is real and 16 bits wide, the mixer is in ‘bypassed’ mode, I use a decimation of 8 samples and ejects 1 sample in each clock cycle, which means that the necessary clock is 153.6 MHz since a reference clock of 1228.8 MHz (sample rate = 1228.8 MSPS) is being used.
To achieve my goal I followed the steps of @cathalmccabe during his DMA tutorial and it worked successfully, the problem comes when I try to store the data acquired by the ADC.
Reading in many blogs and topics of this support, I have noticed that the RF Data Converter does not send the TLAST signal needed by the DMA. That is why in the design shown above I use the ‘Subset Converter’ block that generates the TLAST signal every 256 cycles. The signal is then fed into a FIFO that has a depth of 32768 samples and finally reaches the DMA block. Now I am going to show you the error that I suffer in Jupyter:
CODE:

RESULT:

Signal corrupted (after sample 32768):

As you can see, I am receiving a 100 kHz sine wave that looks correct up to sample 32768. This leads me to think that the FIFO is being filled and subsequently the signal is corrupted. Subsequently the signal is being acquired correctly in the PS in 256-sample spans.
I had also tried three other possibilities:
-
Without using FIFO and without using the ‘Subset Converter’ block:
In this case, the DMA is able to collect the maximum amount of samples allowed (67108863 bytes) but since it does not receive the TLAST signal, the process gets stuck in the ‘wait()’ function and I cannot make a data request to the DMA again because ‘the DMA is not idle’. -
Without using FIFO but using the ‘Subset Converter’ block:
In this case, the DMA does receive the TLAST signal but nevertheless, in each of the iterations in which a write to the PS memory is requested by the DMA there is a loss of samples (I suppose due to the delay caused in each write) very similar to the one seen in the previous image (in the section after the first 32768 samples). -
Using the ‘tlast generator’ block of the XILINX reference design:
But I have not managed to make it work properly as I get the same result as in auxiliary possibility 1.
How could I manage to store in the PS an amount of samples defined by the buffer size? That is, I want to be able to store X samples in the PS continuously. It is not a problem if between two write iterations by the DMA in the PS there is a small delay causing a phase error.
Thank you very much for your time, I hope you can help me,
Jorge.








