
Hi everyone! , I am using PYNQ image version 3.0.1 and Vivado 2022.2 and currently facing a DMA wait() error as I am trying to run a validation test and measure inference time for image processing application.
Following are the schematics and all IP config settings. The dut_0 IP you may be seeing is an HLS generated ip whose I/O interfaces are ap_fifo through which I want to send an array of image pixel values via DMA using AXI streaming interface.
design__bd.pdf (277.7 KB)
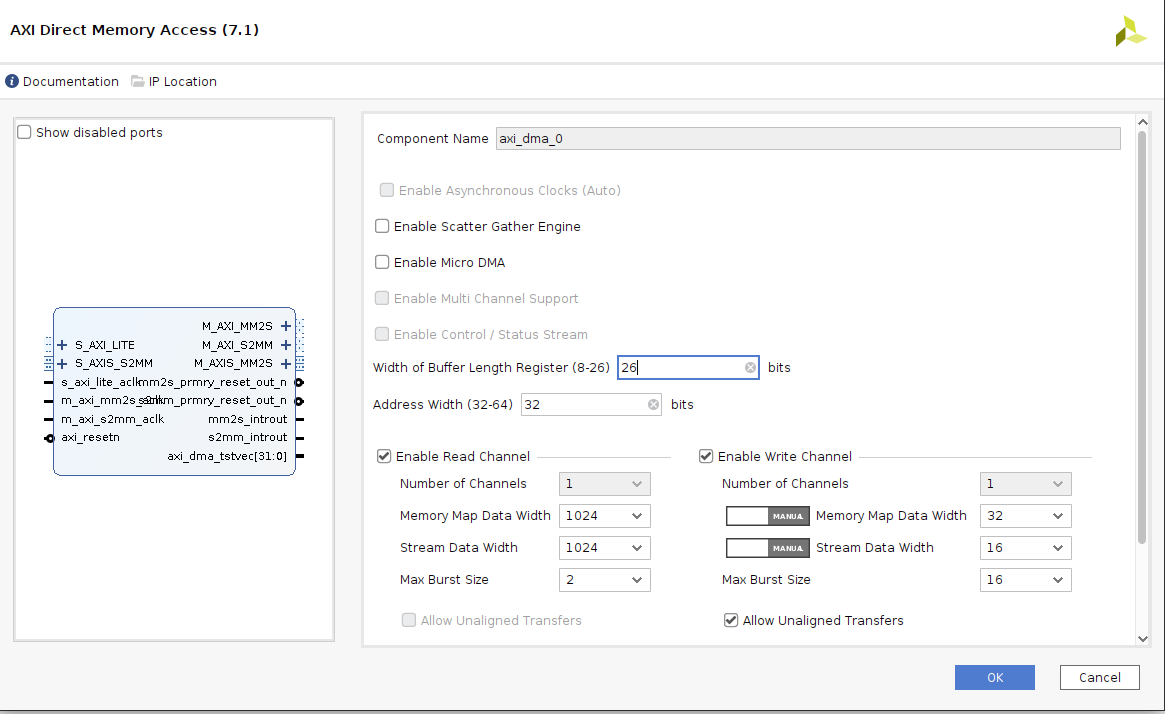
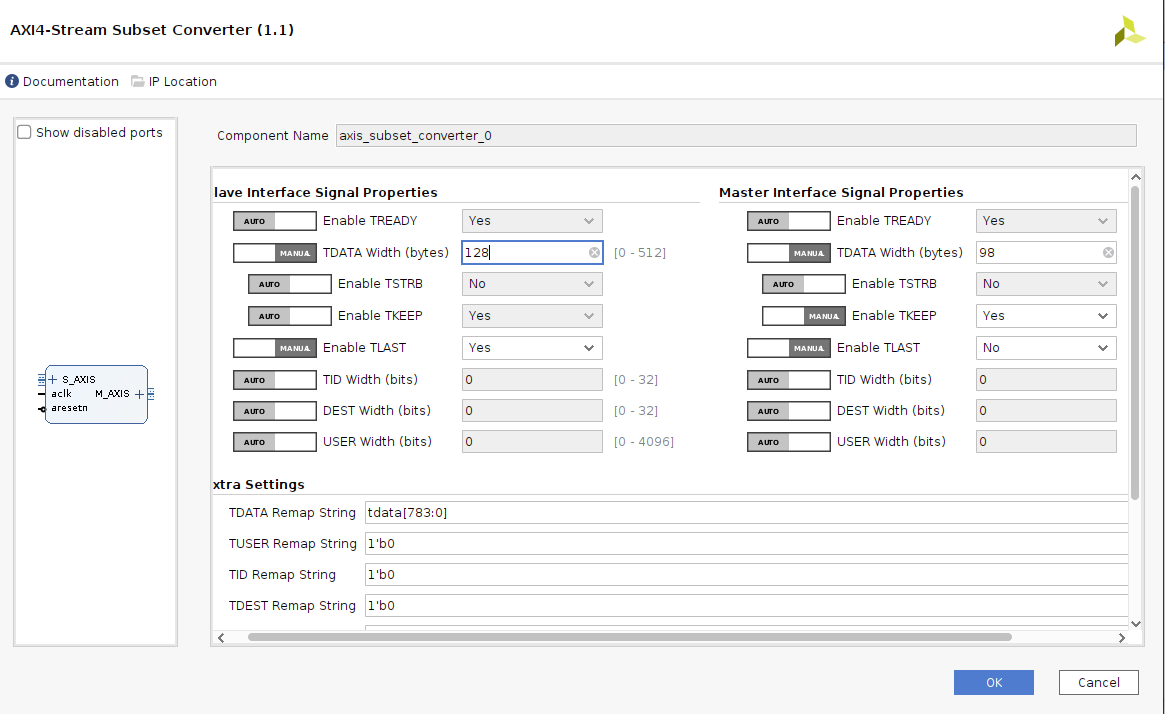
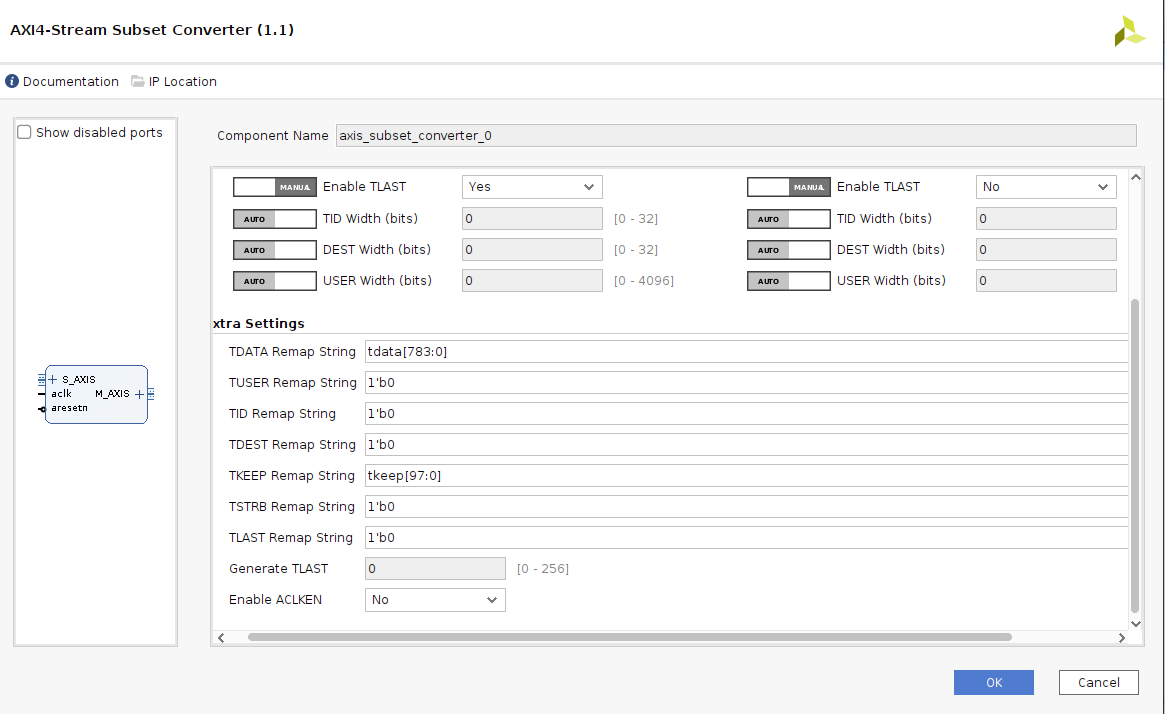
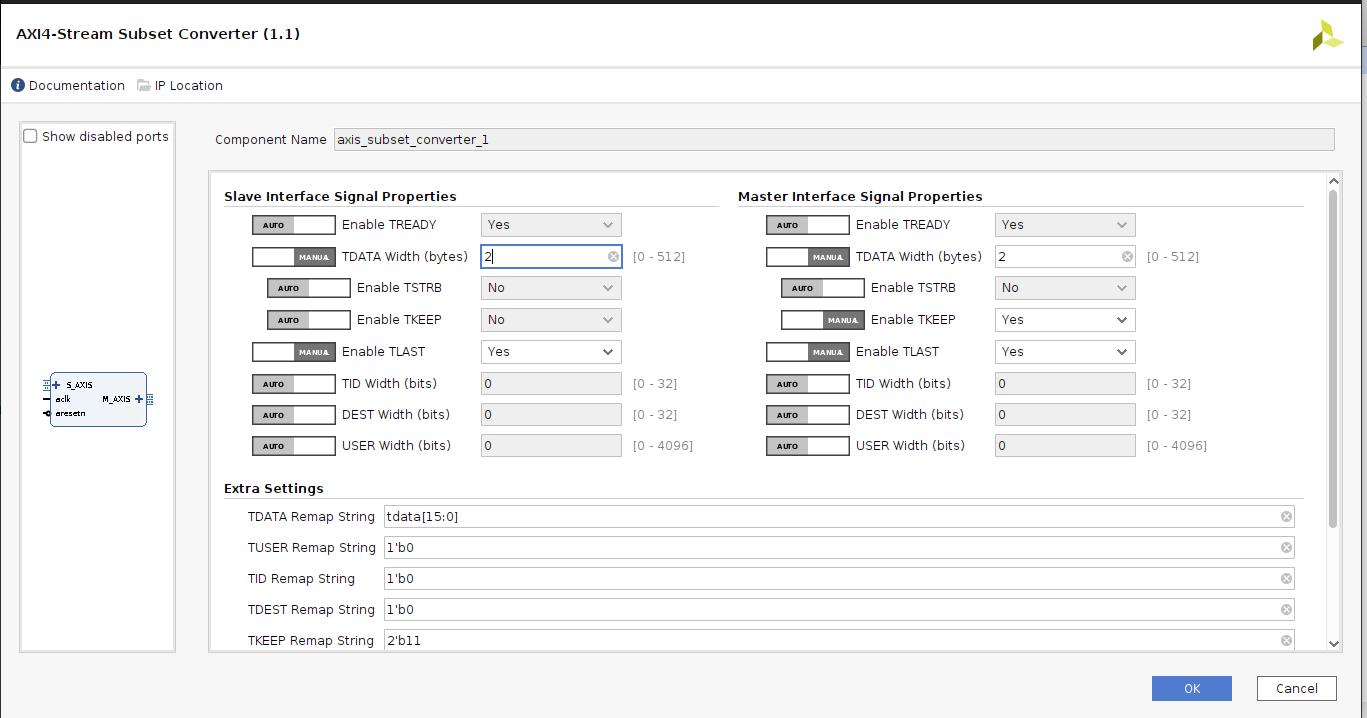
The error I am facing is when trying to run inference is as follows with the code
from datetime import datetime
import numpy as np
from pynq import Overlay, allocate
class HardwareOverlay(Overlay):
def __init__(
self, bitfile_name, x_shape, y_shape, dtype=np.float32, dtbo=None, download=True, ignore_version=False, device=None
):
super().__init__(bitfile_name, dtbo=None, download=True, ignore_version=False, device=None)
self.sendchannel = self.axi_dma_0.sendchannel
self.recvchannel = self.axi_dma_0.recvchannel
self.input_buffer = allocate(shape=x_shape, dtype=dtype)
self.output_buffer = allocate(shape=y_shape, dtype=dtype)
def _print_dt(self, timea, timeb, N):
dt = timeb - timea
dts = dt.seconds + dt.microseconds * 10**-6
rate = N / dts
print(f"Classified {N} samples in {dts} seconds ({rate} inferences / s)")
return dts, rate
def inference(self, X, debug=True, profile=False, encode=None, decode=None):
"""
Obtain the predictions of the NN implemented in the FPGA.
Parameters:
- X : the input vector. Should be numpy ndarray.
- dtype : the data type of the elements of the input/output vectors.
Note: it should be set depending on the interface of the accelerator; if it uses 'float'
types for the 'data' AXI-Stream field, 'np.float32' dtype is the correct one to use.
Instead if it uses 'ap_fixed<A,B>', 'np.intA' is the correct one to use (note that A cannot
any integer value, but it can assume {..., 8, 16, 32, ...} values. Check `numpy`
doc for more info).
In this case the encoding/decoding has to be computed by the PS. For example for
'ap_fixed<16,6>' type the following 2 functions are the correct one to use for encode/decode
'float' -> 'ap_fixed<16,6>':
```
def encode(xi):
return np.int16(round(xi * 2**10)) # note 2**10 = 2**(A-B)
def decode(yi):
return yi * 2**-10
encode_v = np.vectorize(encode) # to apply them element-wise
decode_v = np.vectorize(decode)
```
- profile : boolean. Set it to `True` to print the performance of the algorithm in term of `inference/s`.
- encode/decode: function pointers. See `dtype` section for more information.
- return: an output array based on `np.ndarray` with a shape equal to `y_shape` and a `dtype` equal to
the namesake parameter.
"""
if profile:
timea = datetime.now()
if encode is not None:
X = encode(X)
self.input_buffer[:] = X
self.sendchannel.transfer(self.input_buffer)
self.recvchannel.transfer(self.output_buffer)
if debug:
print("Transfer OK")
self.sendchannel.wait()
if debug:
print("Send OK")
self.recvchannel.wait()
if debug:
print("Receive OK")
# result = self.output_buffer.copy()
if decode is not None:
self.output_buffer = decode(self.output_buffer)
if profile:
timeb = datetime.now()
dts, rate = self._print_dt(timea, timeb, len(X))
return self.output_buffer, dts, rate
else:
return self.output_buffer
for data, targets in iter(test_loader):
testdata = data.numpy()
lables = targets.numpy()
infer = HardwareOverlay('design_1.bit', testdata.shape, lables.shape)
y_hw, latency , throughput = infer.inference(testdata, profile=True)
break
here the test_loader is a pytorch dataloader object
error as follows (this is produced when I interrupt the kernel execution, if not interrupted then cell runs forever)
output stuck (no acknowledgement of completed transfer)
Transfer OK
error after interrupt
KeyboardInterrupt Traceback (most recent call last)
Input In [4], in <cell line: 28>()
30 lables = targets.numpy()
31 nn = NeuralNetworkOverlay('snn.bit', testdata.shape, lables.shape)
---> 32 y_hw, latency , throughput = nn.predict(testdata, profile=True)
33 break
Input In [1], in NeuralNetworkOverlay.predict(self, X, debug, profile, encode, decode)
58 if debug:
59 print("Transfer OK")
---> 60 self.sendchannel.wait()
61 if debug:
62 print("Send OK")
File /usr/local/share/pynq-venv/lib/python3.10/site-packages/pynq/lib/dma.py:181, in _SDMAChannel.wait(self)
179 if error & 0x40:
180 raise RuntimeError("DMA Decode Error (invalid address)")
--> 181 if self.idle:
182 break
183 if not self._flush_before:
File /usr/local/share/pynq-venv/lib/python3.10/site-packages/pynq/lib/dma.py:80, in _SDMAChannel.idle(self)
73 @property
74 def idle(self):
75 """True if the DMA engine is idle
76
77 `transfer` can only be called when the DMA is idle
78
79 """
---> 80 return self._mmio.read(self._offset + 4) & 0x02 == 0x02
KeyboardInterrupt:
As you can see its stuck at sendchannel.wait(). I know its because of DMA not being idle but i have configured the DMA for transfer already using the control register for continuous operation. I have also gone through the DMA debugging posts on community forum but still no luck. I cannot get ILA to work as I have completely exhausted my BRAM so any help or advice is welcomed how should I solve this issue.
Also please let me know that the above IPI block diagram is correct or not as at this point I am really not sure.