PYNQ DFX Partial Reconfiguration Issue
Hello,
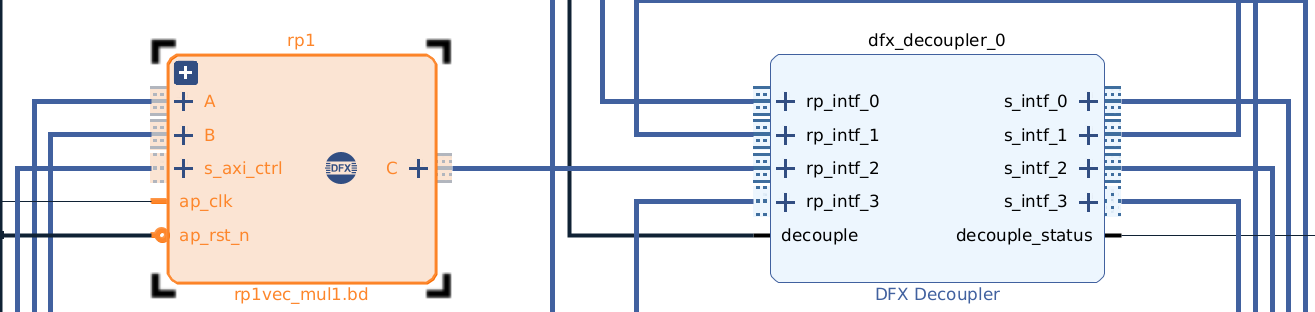
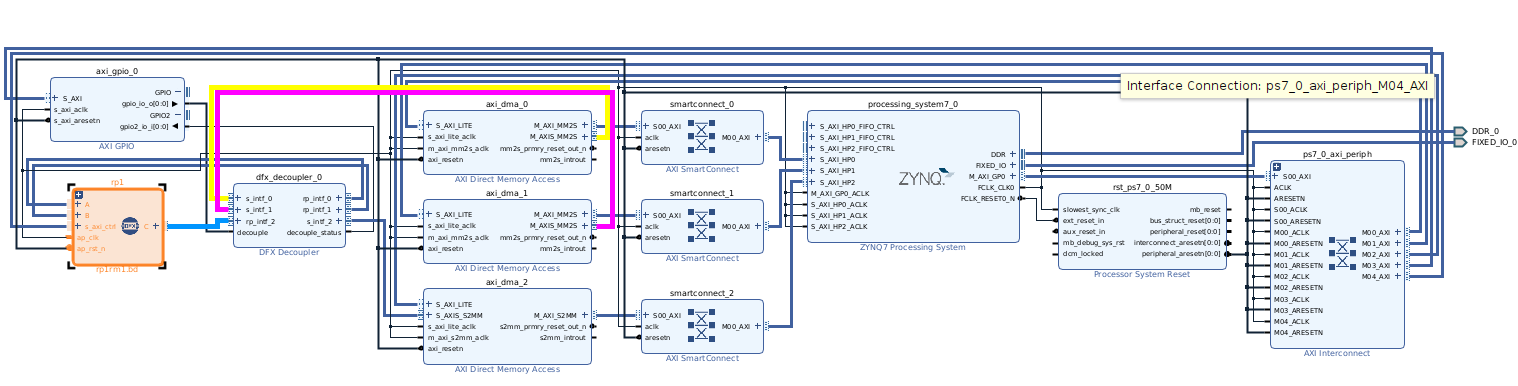
I’m a beginner learning Dynamic Function eXchange (DFX) partial reconfiguration on PYNQ 3.1 with Ubuntu 22.04.5 LTS and Vivado 2024.1. I built a base overlay with one reconfigurable partition (RP) containing two RMs: vec_add and vec_mul.
Here is my BD:
Base Python Code
from pynq import Overlay
import time
# Load base overlay
print("Loading base overlay...")
ol = Overlay("design_1_wrapper_full.bit")
print("Full overlay loaded")
# Decoupler GPIO
gpio = ol.axi_gpio_0
# Load vec_add partial
gpio.write(0, 1) # Decouple RP
time.sleep(0.2)
ol.rp1.download("rm1_partial.bit")
time.sleep(0.5)
gpio.write(0, 0) # Reconnect RP
print("vec_add partial loaded")
# Load vec_mul partial
gpio.write(0, 1)
time.sleep(0.2)
ol.rp1.download("rm2_partial.bit")
time.sleep(0.5)
gpio.write(0, 0)
print("vec_mul partial loaded")
Observed Output
1. Loading base overlay...
Full overlay loaded
vec_add partial loaded
TEST 2: Load rm2_partial.bit (vec_mul)
vec_mul partial loaded
DFX Partial Bitstream Reload Test Complete!
Problem
When running the RM computations with the DMAs, I get stuck or garbage results:
Base design loaded
IP blocks: ['rp1', 'axi_dma_0', 'axi_dma_1', 'axi_dma_2', 'axi_gpio_0', 'processing_system7_0']
Decoupler: ON
Decoupler: OFF
VecAdd out: [524288 0 0 0 0]
Expected: [ 0 3 6 9 12]
✗ VecAdd FAILED
Decoupler: ON
Decoupler: OFF
VecMul out: [524288 0 0 0 0]
Expected: [ 0 2 8 18 32]
✗ VecMul FAILED
Steps Tried
- Verified GPIO decoupler toggling.
- Added sleep after RP decouple and download.
- Checked DMA channels after partial load.
Edited: Update
I checked the HP port it was 32 i fixed to 64. Also i fixed Apetures. I got vec_add only working.
from pynq import Overlay, allocate
import time
import numpy as np
# Load the base overlay once
overlay = Overlay("design_1.bit")
gpio = overlay.axi_gpio_0
dmaA = overlay.axi_dma_0
dmaB = overlay.axi_dma_1
dmaC = overlay.axi_dma_2
# Define shared data buffers
N = 16
input_a = allocate(shape=(N,), dtype=np.int32)
input_b = allocate(shape=(N,), dtype=np.int32)
output_c = allocate(shape=(N,), dtype=np.int32)
for i in range(N):
input_a[i] = i + 1
input_b[i] = (i + 1) * 10
# --- Run Partial Bitstream 1 (vec_add) ---
print("--- Running vec_add ---")
gpio.write(0, 1) # Decouple ON
time.sleep(0.2)
overlay.rp1.download('rp1rm1_inst_0.bit')
time.sleep(0.5)
gpio.write(0, 0) # Decouple OFF
time.sleep(0.2)
# GET the IP *after* the partial bitstream is loaded
vec_add = overlay.rp1.vec_add_0
# Configure and run the new IP
vec_add.write(0x00, 0x00) # reset
vec_add.write(0x10, N) # set length
time.sleep(0.05)
vec_add.write(0x00, 0x01) # start
# Perform DMA transfers (starting receiver first is a good practice)
dmaC.recvchannel.transfer(output_c)
time.sleep(0.01)
dmaA.sendchannel.transfer(input_a)
dmaB.sendchannel.transfer(input_b)
dmaA.sendchannel.wait()
dmaB.sendchannel.wait()
dmaC.recvchannel.wait()
print("Input A:", input_a)
print("Input B:", input_b)
print("Output C:", output_c)
print("Expected :", input_a + input_b)
# --- Run Partial Bitstream 2 (vec_mul) ---
print("\n--- Running vec_mul ---")
gpio.write(0, 1) # Decouple ON
time.sleep(0.2)
overlay.rp1.download('rp1rm2_inst_0.bit')
time.sleep(0.5)
gpio.write(0, 0) # Decouple OFF
time.sleep(0.2)
vec_mul = overlay.rp1.vec_mul_0
# CLEAR output buffer
output_c[:] = 0
# Reset IP but DON'T start yet
vec_mul.write(0x00, 0x00)
time.sleep(0.1)
vec_mul.write(0x10, N)
time.sleep(0.05)
# Start DMA transfers first
dmaC.recvchannel.transfer(output_c)
time.sleep(0.01)
dmaA.sendchannel.transfer(input_a)
dmaB.sendchannel.transfer(input_b)
time.sleep(0.05)
# NOW start the IP
vec_mul.write(0x00, 0x01)
dmaA.sendchannel.wait()
dmaB.sendchannel.wait()
dmaC.recvchannel.wait()
print("Output C:", output_c)
print("Expected :", input_a * input_b)
Output
--- Running vec_add ---
Input A: [ 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16]
Input B: [ 10 20 30 40 50 60 70 80 90 100 110 120 130 140 150 160]
Output C: [ 11 22 33 44 55 66 77 88 99 110 121 132 143 154 165 176]
Expected : [ 11 22 33 44 55 66 77 88 99 110 121 132 143 154 165 176]
--- Running vec_mul ---
Output C: [1675100160 1675100160 1675164988 1675164988 10 40
0 0 0 0 0 0
0 0 0 0]
Expected : [ 10 40 90 160 250 360 490 640 810 1000 1210 1440 1690 1960
2250 2560]
Question
How should I properly isolate the RP, load the partial, and ensure DMAs are working correctly? Do I need to reinitialize DMA channels after every partial load?
Is there anything in my design that could cause the DMA to fail or produce garbage results after a partial load?
Any guidance or example code for safe partial reconfiguration with DMAs would be very appreciated.